近日,阿里云人工智能平台PAI与浙江大学吴健、应豪超老师团队合作论文《Arithmetic Feature Interaction is Necessary for Deep Tabular Learning》正式在国际人工智能顶会AAAI-2024上发表。本项工作聚焦于深度表格学习中的一个核心问题:在处理结构化表格数据(tabular data)时,深度模型是否拥有有效的归纳偏差(inductive bias)。我们提出算术特征交互(arithmetic feature interaction)对深度表格学习是至关重要的假设,并通过创建合成数据集以及设计实现一种支持上述交互的AMFormer架构(一种修改的Transformer架构)来验证这一假设。实验结果表明,AMFormer在合成数据集表现出显著更优的细粒度表格数据建模、训练样本效率和泛化能力,并在真实数据的对比上超过一众基准方法,成为深度表格学习新的SOTA(state-of-the-art)模型。
结构化表格数据——这些数据往往以表(Table)的形式存储于数据库或数仓中——作为一种在金融、市场营销、医学科学和推荐系统等多个领域广泛使用的重要数据格式,其分析一直是机器学习研究的热点。表格数据(图1)通常同时包含数值型(numerical)特征和类目型(categorical)特征,并往往伴随有特征缺失、噪声、类别不平衡(class imblanance)等数据质量问题,且缺少时序性、局部性等有效的先验归纳偏差,极大地带来了分析上的挑战。传统的树集成模型(如,XGBoost、LightGBM、CatBoost)因在处理数据质量问题上的鲁棒性,依然是工业界实际建模的主流选择,但其效果很大程度依赖于特征工程产出的原始特征质量。
随着深度学习的流行,研究者试图引入深度学习端到端建模,从而减少在处理表格数据时对特征工程的依赖。相关的研究工作至少可以可以分成四大类:(1)在传统建模方法中叠加深度学习模块(通常是多层感知机MLP),如Wide&Deep、DeepFMs;(2)形状函数(shape function)采用深度学习建模的广义加性模型(generalized additive model),如 NAM、NBM、SIAN;(3)树结构启发的深度模型,如NODE、Net-DNF;(4)基于Transformer架构的模型,如AutoInt、DCAP、FT-Transformer。尽管如此,深度学习在表格数据上相比树模型的提升并不显著且持续,其有效性仍然存在疑问,表格数据因此被视为深度学习尚未征服的最后堡垒。
我们认为现有的深度表格学习方法效果不尽如人意的关键症结在于没有找到有效的建模归纳偏差,并进一步提出算术特征交互对深度表格学习是至关重要的假设。本节介绍我们通过创建一个合成数据集,并对比引入算数特征交互前后的模型效果,来验证该假设。
图2:合成数据集上的结果对比。图中+x%表示AMFormer相比Transformer的相对提升。

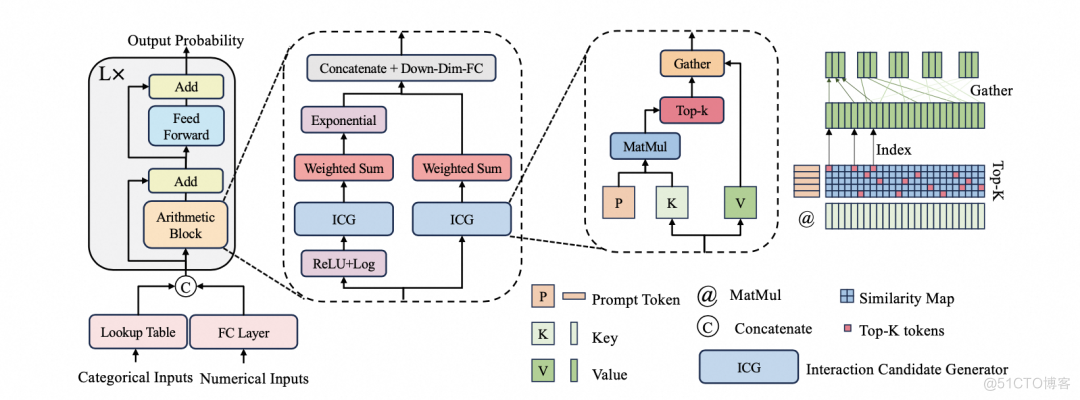
本节介绍AMFormer架构(图3),并重点介绍算数特征交互的引入。AMFormer架构借鉴了经典的Transformer框架,并引入了Arithmetic Block来增强模型的算术特征交互能力。在AMFormer中,我们首先将原始特征转换为具有代表性的嵌入向量,对于数值特征,我们使用一个1输入d输出的线性层;对于类别特征,则使用一个d维的嵌入查询表。之后,这些初始嵌入通过L个顺序层进行处理,这些层增强了嵌入向量中的上下文和交互元素。每一层中的算术模块采用了并行的加法和乘法注意力机制,以刻意促进算术特征之间的交互。为了促进梯度流动和增强特征表示,我们保留了残差连接和前馈网络。最终,依据这些丰富的嵌九游体育入向量,AMFormer使用分类或回归头部生成最终输出。
算术模块的关键组件包括并行注意力机制和提示标记。为了补偿需要算术特征交互的特征,我们在AMFormer中配置了并行注意力机制,这些机制负责提取有意义的加法和乘法交互候选者。这些交互候选随着会沿着候选维度被串联(concatenate)起来,并通过一个下采样的线性层进行融合,使得AMFormer的每一层都能有效捕捉算术特征交互,即特征上的四则算法运算。为了防止由特征冗余引起的过拟合并提升模型在超大规模特征数据集上的伸缩,我们放弃了原始Transformer架构中平方复杂度的自注意力机制,而是使用两组提示向量(prompt token vectors)作为加法和乘法查询。这种方法为AMFormer提供了有限的特征交互自由度,并且作为一个附带效果,优化了内存占用和训练效率。
以上是AMFormer在架构层引入的主要创新,关于模型更详细的实现细节可以参考原文以及我们的开源实现。

为了进一步展示AMFormer的效果,我们挑选了四个真实数据集进行实验。被挑选数据集覆盖了二分类、多分类以及回归任务,数据集统计如表1所示。

表2:AMFormer以及基准方法的性能对比,其中括号内的数字表示该方法在当前数据集上表现的排名,最优以及次优的结果分别以加粗以及下划线突出。
我们一共测试了包含传统树模型(XGBoost)、树架构深度学习方法(NODE)、高阶特征交互(DCN-V2、DCAP)以及Transformer派生架构(AutoInt、FT-Trans)在内的六个基准算法以及两个AMFormer实现(分别选择AutoInt、FT-Trans做基础架构,即AMF-A和AMF-F),结果汇总在表2中。
在一系列对比实验中,AMFormer表现更突出。结果显示,基于MLP的深度学习方法如DCN-V2在表格数据上的性能不尽如人意,而基于Transformer架构的模型显示出更大的潜力,但未能始终超过树模型XGBoost。我们的AMFormer在四个不同的数据集上,与所有六个基准模型相比,表现一致更优:在分类任务中,它将AutoInt和FT-transformer的准确率或AUC提升至少0.5%,最高达到1.23%(EP)和4.96%(CO);在回归任务中,它也显著减少了平均平方误差。相比其它深度表格学习方法,AMFormer具有更好的鲁棒和稳定性,这使得在性能排序中AMFormer断层式优于其它基准算法,这些实验结果充分证明了AMFormer在深度表格学习中的必要性和优越性。
本工作研究了深度模型在表格数据上的有效归纳偏置。我们提出,算术特征交互对于表格深度学习是必要的,并将这一理念融入Transformer架构中,创建了AMFormer。我们在合成数据和真实世界数据上验证了AMFormer的有效性。合成数据的结果展示了其在精细表格数据建模、训练数据效率以及泛化方面的优越能力。此外,对真实世界数据的广泛实验进一步确认了其一致的有效性。因此,我们相信AMFormer为深度表格学习设定了强有力的归纳偏置。
下一篇:eBPF动手实践系列三:基于原生libbpf库的eBPF编程改进方案
特征选择和稀疏学习子集搜索与评价对象都有很多属性来描述,属性也称为特征(feature),用于刻画对象的某一个特性。对一个学习任务而言,有些属性是关键有用的,而有些属性则可能不必要纳入训练数据。对当前学习任务有用的属性称为相关特征(relevant feature)、无用的属性称为无关特征(irrelevantfeature)。从给定的特征集合中选择出相关特征子集的过程,称为特征选择(featur
0. 简介深度学习中做量化提升运行速度是最常用的方法,尤其是大模型这类非常吃GPU显存的方法。一般是高精度浮点数表示的网络权值以及激活值用低精度(例如8比特定点)来近似表示达到模型轻量化,加速深度学习模型推理,目前8比特推理已经比较成熟。比如int8量化,就是让原来32bit存储的数字映射到8bit存储。int8范围是[-128,127], uint8范围是[0,255]。使用低精度的模型推理的优
解锁数据潜力:从数据中台到数据飞轮的关键转变在当今数据驱动的商业景观中,数据中台已经成为众多企业建立强大数据基础设施的首选框架。然而,随着技术进步和商业需求的变化,仅有数据中台并不足以满足企业的竞争需求。数据飞轮的概念,作为数据中台的进阶版,提出了如何通过持续的数据积累和利用,推动业务增长的策略。这正是每个寻求领先的企业需要关注的转变。首先,我们必须认识到数据中台确实是构建数据飞轮的基础。数据
目录一,深度学习二,神经网络1,完全连接前馈神经网络2,神经网络的层次一,深度学习深度学习是机器学习的一种方法。在过去几十年的发展中,它大量借鉴了我们关于人脑(神经网络)、统计学和应用
深度学习(Deep Learning)是人工智能领域中的一个重要分支,也是目前最热门的研究方向之一。它是通过模仿人类大脑的工作原理,利用人工神经网络对大量数据进行训练和学习,从而实现对复杂问题的分析和解决。在深度学习中,最常用的模型是神经网络(Neural Network)。神经网络由多个神经元(Neuron)组成,每个神经元都有多个输入和一个输出。通过不断调整神经元之间的连接权重,神经网络可
4.2、初级(浅层)特征表示 既然像素级的特征表示方法没有作用,那怎样的表示才有用呢? 1995 年前后,Bruno Olshausen和 David Field 两位学者任职 Cornell University,他们试图同时用生理学和计算
# Halcon Deep Learning深度学习安装## 引言深度学习作为人工智能领域的热门技术,已经在图像处理、语音识别、自然语言处理等领域取得了很大的突破。在工业和生产环境中,Halcon是一款强大的视觉处理软件,可以用于机器视觉系统的开发和部署。为了充分发挥Halcon的潜力,我们可以将深度学习与Halcon相结合,从而实现更高级的图像处理和分析。本文将介绍如何在Halcon
Deep Learning是机器学习中一个非常接近AI的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,近期研究了机器学习中一些深度学习的相关知识,本文给出一些非常实用的资料和心得。 Key Words:有监督学习与无监督学习。分类、回归。密度预计、聚类,深度学习,Sparse DBN, 1.
深度(Depth)从一个输入中产生一个输出所涉及的计算可以通过一个流向图(flow graph)来表示:流向图是一种能够表示计算的图,在这种图中每一个节点表示一个基本的计算并且一个计算的值(计算的结果被应用到这个节点的孩子节点的值)。考虑这样一个计算集合,它可以被允许在每一个节点和可能的图结构中,并定义了一个函数族。输入节点没有孩子,输出节点没有父亲。对于表达 的流向图,可以通过一个有两
更深层次的神经网络更难训练。我们提出了一个残差学习框架,以简化对比以前使用的网络更深入的网络的训练。我们根据层输入显式地将层重新表示为学习残差函数( learning residual functions),而不是学习未定义函数。我们提供了综合的经验证据,表明这些残差网络易于优化,并且可以从大幅度增加的深度中获得精度。在ImageNet数据集上,我们估计残差网络的深度可达152层--是vgg网络的
?本文主要介绍了Self-Attention产生的背景以及解析了具体的网络模型一、Introduction统一、固定长度的向量来表示。比如NLP中长短不一的句子。此外,我们需要输出的数据有时候也会复杂,比如一组向量中每一个向量有一个输出(词性标注),或者一组向量有一个输出,或者输出的数量让机器自己决定(即seq2seq任务,比如中英文翻译)Fully-connected,然后每一个向量
上一周的回顾过去的一周真的发生了很多意想不到、惊心动魄的事情,从大学四年最后一次体测到唐奖竞争,从小IG力挽狂澜到RNG遗憾折戟,生活可谓是充满了无数的可能。也正是因为这样,我们的生活才不至于那么乏味,像工厂流水线生产一样标准化、制度化,而随时都可能发生一段令人难忘的奇妙冒险。做学问、努力学习的过程其实也是这样,不仅要脚踏实地
九、Deep Learning的常用模型或者方法9.1、AutoEncoder自动编码器 Deep Learning最简单的一种方法是利用人工神经网络的特点,人工神经网络(ANN)本身就是具有层次结构的系统,如果给定一个神经网络,我们假设其输出与输入是相同的,然后训练调整其参数,得到每一层中的权重。自然地,我们就得
电脑QQ浏览器中在地址栏显示最常访问功能怎么开启QQ浏览器是我们现在经常在电脑上使用的浏览器软件之一,为了方便我们的访问我们可以开启浏览器中的在地址栏显示最常访问的功能。接下来小编就教大家怎样操作。具体如下:1. 首先我们打开电脑进入到桌面,然后找到QQ浏览器图标点击打开。2. 进入到软件界面之后,我们点击右上角的三条横线. 然后在我们软件的右上角会打开菜单,我们点击菜单中的设置选项。4.
一、概述过期时间TTL表示可以对消息设置预期的时间,在这个时间内都可以被消费者接收获取;过了之后消息将自动被删除。RabbitMQ可以对消息和队列设置TTL。目前有两种方法可以设置。第一种方法是通过队列属性设置,队列中所有消息都有相同的过期时间。 第二种方法是对消息进行单独设置,每条消息TTL可以不同。 如果上述两种方法同时使用,则消息的过期时间以两者之间TTL较小的那个数值为准。消息在队列的生存
mac结构:mac是unix结构,遵循基本的unix架构:参考链接:我这里主要说明下环境变量的配置(根据百度出来的配置很坑爹)mac的环境配置是有顺序的:参考链接:
戴尔R710服务器硬盘出现告警(绿黄灯闪),解决方法2015年11月7日机房打来电话说,一台服务器硬盘出现异常,去机房查看硬盘灯闪的情况,先闪绿灯,再闪黄灯。戴尔R710服务器, 双300G硬盘做了raid1,其中有一块硬盘出现告警,服务器正常工作。给戴尔客服打电话,描述相关的问题。然后戴尔客服通邮件,并且发送解决文档给我,主要获取硬盘的日志。1.详情查看:《Dell PowerEdge 服务器硬


















