以下是我心目中深度学习的顶尖算法,它们在创新性、应用价值和影响力方面都占据重要地位。

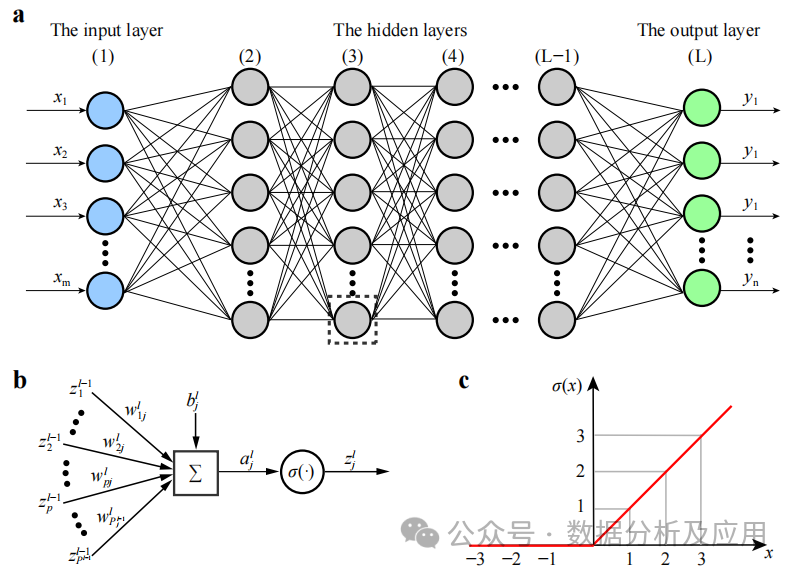
背景:深度神经网络(DNN)也叫多层感知机,是最普遍的深度学习算法,发明之初由于算力瓶颈而饱受质疑,直到近些年算力、数据的爆发才迎来突破。
DNN是一种神经网络模型,它包含多个隐藏层。在该模型中,每一层将输入传递给下一层,并利用非线性激活函数引入学习的非线性特性。通过叠加这些非线性变换,DNN可以学习输入数据的复杂特征表示。
模型训练涉及使用反向传播算法和梯度下降优化算法来不断调整权重。在训练中,通过计算损失函数对权重的梯度,然后利用梯度下降或其他优化算法来更新权重,以使损失函数最小化。
优点:能够学习输入数据的复杂特征,并捕获非线性关系。具有强大的特征学习和表示能力。
网络深度增加会导致梯度消失问题加剧,训练不稳定。此外,模型容易陷入局部最小值,需要复杂的初始化策略和正则化技术。
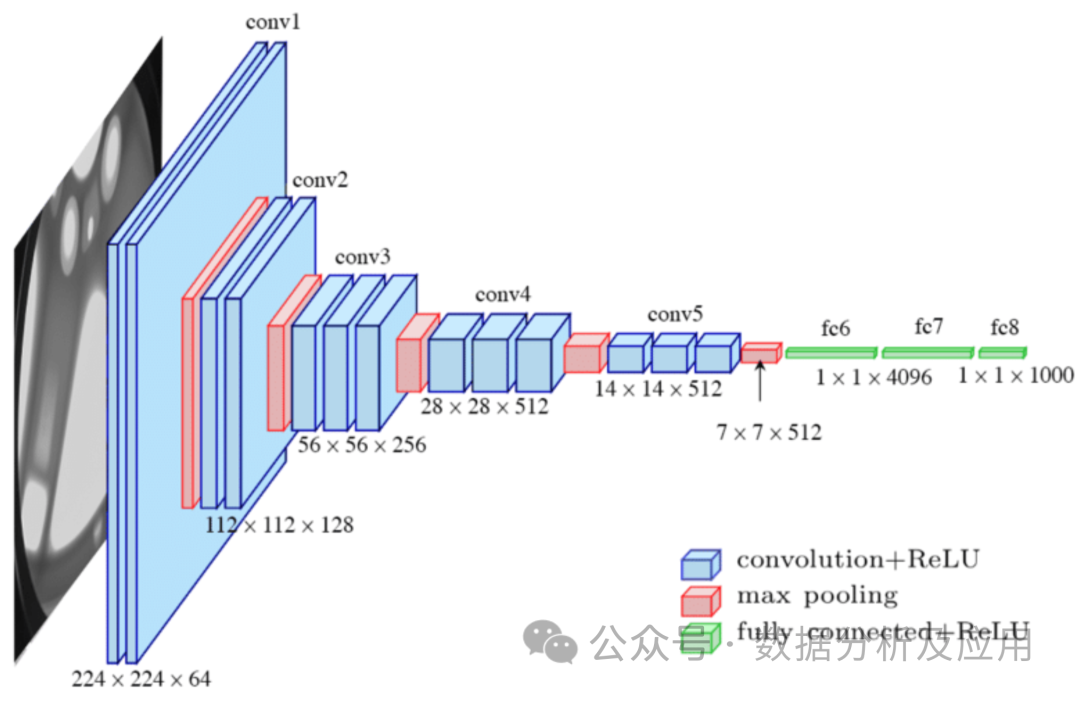
模型原理:卷积神经网络(CNN)是一种专门为处理图像数据而设计的神经网络,由Lechun大佬设计的Lenet是CNN的开山之作。CNN通过使用卷积层来捕获局部特征,并通过池化层来降低数据的维度。卷积层对输入数据进行局部卷积操作,并使用参数共享机制来减少模型的参数数量。池化层则对卷积层的输出进行下采样,以降低数据的维度和计算复杂度。这种结构特别适合处理图像数据。
模型训练涉及使用反向传播算法和梯度下降优化算法来不断调整权重。在训练中,通过计算损失函数对权重的梯度,然后利用梯度下降或其他优化算法来更新权重,以使损失函数最小化。
优点:能够有效地处理图像数据,并捕获局部特征。具有较少的参数数量,降低了过拟合的风险。
缺点:对于序列数据或长距离依赖关系可能不太适用。可能需要对输入数据进行复杂的预处理。
ResNet通过引入“残差块”来解决深度神经网络中的梯度消失和模型退化问题。残差块由一个“跳跃连接”和一个或多个非线性层组成,使得梯度可以直接从后面的层反向传播到前面的层,从而更好地训练深度神经网络。通过这种方式,ResNet能够构建非常深的网络结构,并在多个任务上取得了优异的性能。
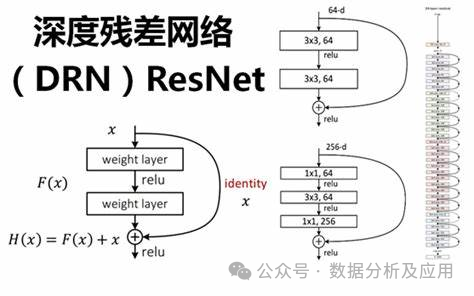
ResNet的训练通常使用反向传播算法和优化算法(如随机梯度下降)。在训练过程中,通过计算损失函数关于权重的梯度,并使用优化算法更新权重,以最小化损失函数。此外,为了加速训练过程和提高模型的泛化能力,还可以采用正则化技术、集成学习等方法。
解决了梯度消失和模型退化问题:通过引入残差块和跳跃连接,ResNet能够更好地训练深度神经网络,避免了梯度消失和模型退化的问题。
构建了非常深的网络结构:由于解决了梯度消失和模型退化问题,ResNet能够构建非常深的网络结构,从而提高了模型的性能。
参数调优难度大:ResNet的参数数量众多,需要花费大量时间和精力进行调优和超参数选择。
在这个简化版的示例中,我们将演示如何使用Keras库构建一个简单的ResNet模型。
LSTM通过引入“门控”机制来控制信息的流动,从而解决梯度消失和模型退化问题。LSTM有三个门控机制:输入门、遗忘门和输出门。输入门决定了新信息的进入,遗忘门决定了旧信息的遗忘,输出门决定最终输出的信息。通过这些门控机制,LSTM能够在长期依赖问题上表现得更好。
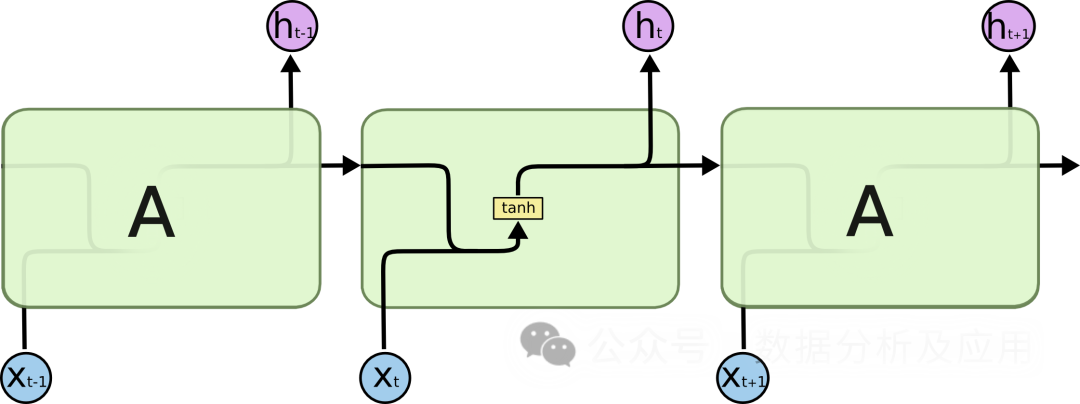
LSTM的训练通常使用反向传播算法和优化算法(如随机梯度下降)。在训练过程中,通过计算损失函数关于权重的梯度,并使用优化算法更新权重,以最小化损失函数。此外,为了加速训练过程和提高模型的泛化能力,还可以采用正则化技术、集成学习等方法。
解决梯度消失和模型退化问题:通过引入门控机制,LSTM能够更好地处理长期依赖问题,避免了梯度消失和模型退化的问题。
构建非常深的网络结构:由于解决了梯度消失和模型退化问题,LSTM能够构建非常深的网络结构,从而提高了模型的性能。
对初始化权重敏感:LSTM对初始化权重的选择敏感度高,如果初始化权重不合适,可能会导致训练不稳定或过拟合问题。
Word2Vec模型基于神经网络,利用输入的词预测其上下文词。在训练过程中,模型尝试学习到每个词的向量表示,使得在给定上下文中出现的词与目标词的向量表示尽可能接近。这种训练方式称为“Skip-gram”或“Continuous Bag of Words”(CBOW)。
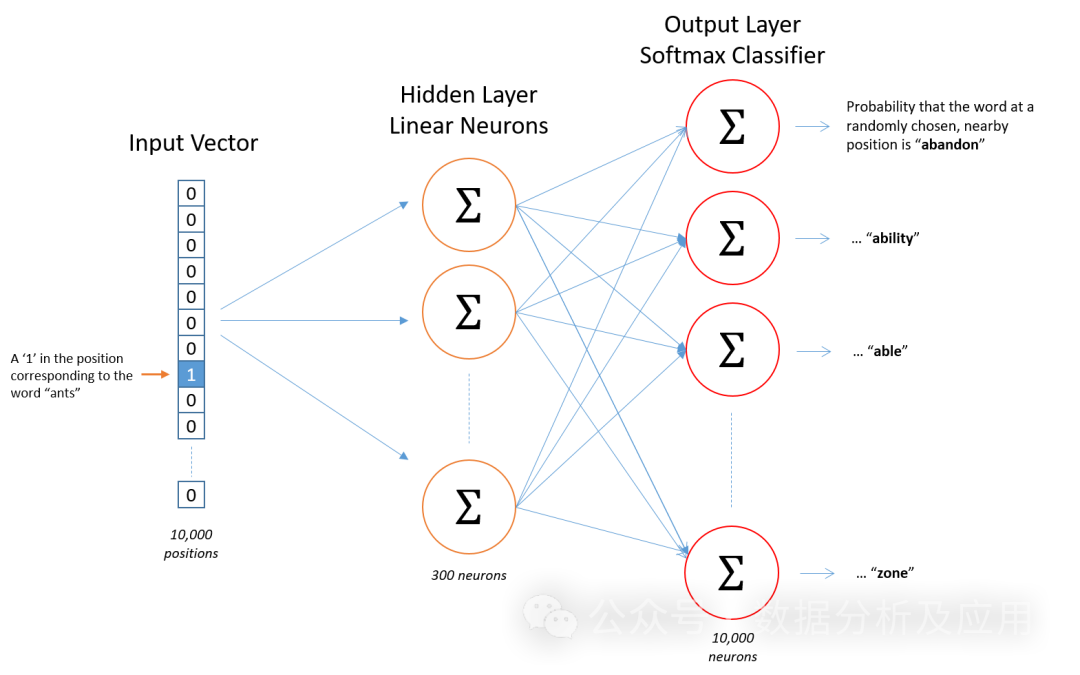
训练Word2Vec模型需要大量的文本数据。首先,将文本数据预处理为一系列的词或n-gram。然后,使用神经网络训练这些词或n-gram的上下文。在训练过程中,模型会不断地调整词的向量表示,以最小化预测误差。
: Word2Vec只考虑了固定大小的上下文,可能会忽略更远的依赖关系。
: Word2Vec的性能高度依赖于超参数(如向量维度、窗口大小、学习率等)的设置。
Word2Vec被广泛应用于各种自然语言处理任务,如文本分类、情感分析、信息提取等。例如,可以使用Word2Vec来识别新闻报道的情感倾向(正面或负面),或者从大量文本中提取关键实体或概念。
在深度学习的早期阶段,卷积神经网络(CNN)在图像识别和自然语言处理领域取得了显著的成功。然而,随着任务复杂度的增加,序列到序列(Seq2Seq)模型和循环神经网络(RNN)成为处理序列数据的常用方法。尽管RNN及其变体在某些任务上表现良好,但它们在处理长序列时容易遇到梯度消失和模型退化问题。为了解决这些问题,Trans
former模型被提出。而后的GPT、Bert等大模型都是基于Transformer实现了卓越的性能!
Transformer模型主要由两部分组成:编码器和解码器。每个部分都由多个相同的“层”组成。每一层包含两个子层:自注意力子层和线性前馈神经网络子层。自注意力子层利用点积注意力机制计算输入序列中每个位置的表示,而线性前馈神经网络子层则将自注意力层的输出作为输入,并产生一个输出表示。此外,编码器和解码器都包含一个位置编码层,用于捕获输入序列中的位置信息。
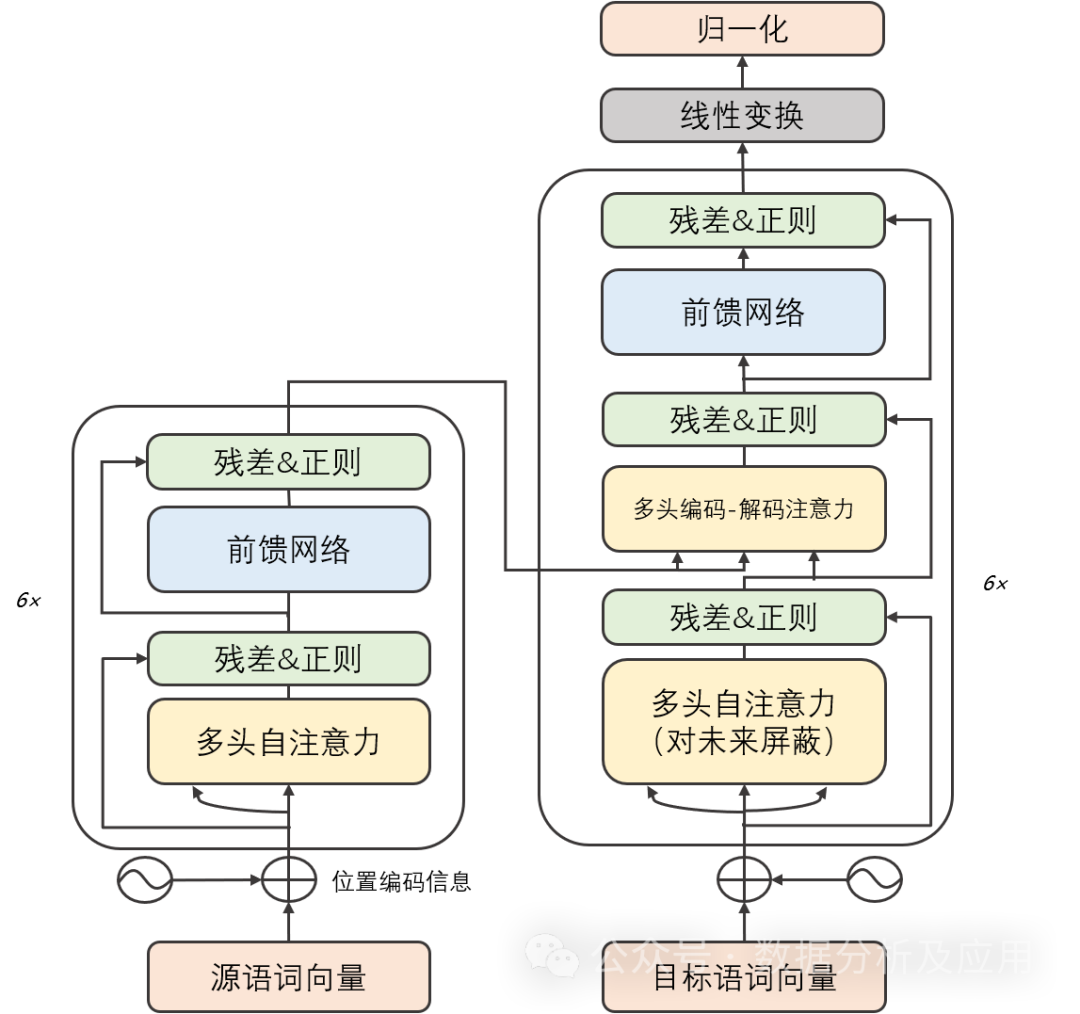
Transformer模型的训练通常使用反向传播算法和优化算法(如随机梯度下降)。在训练过程中,通过计算损失函数关于权重的梯度,并使用优化算法更新权重,以最小化损失函数。此外,为了加速训练过程和提高模型的泛化能力,还可以采用正则化技术、集成学习等方法。
解决了梯度消失和模型退化问题:由于Transformer模型采用自注意力机制,它能够更好地捕捉序列中的长期依赖关系,从而避免了梯度消失和模型退化的问题。
高效的并行计算能力:由于Transformer模型的计算是可并行的,因此在GPU上可以快速地进行训练和推断。
对初始化权重敏感:Transformer模型对初始化权重的选择敏感度高,如果初始化权重不合适,可能会导致训练不稳定或过拟合问题。
无法学习长期依赖关系:尽管Transformer模型解决了梯度消失和模型退化问题,但在处理非常长的序列时仍然存在挑战。
Transformer模型在自然语言处理领域有着广泛的应用场景,如机器翻译、文本分类、文本生成等。此外,Transformer模型还可以用于图像识别、语音识别等领域。
GAN由两部分组成:生成器(Generator)和判别器(Discriminator)。生成器的任务是生成假数据,而判别器的任务是判断输入的数据是来自真实数据集还是生成器生成的假数据。在训练过程中,生成器和判别器进行对抗,不断调整参数,直到达到一个平衡状态。此时,生成器生成的假数据足够逼真,使得判别器无法区分真实数据与假数据。
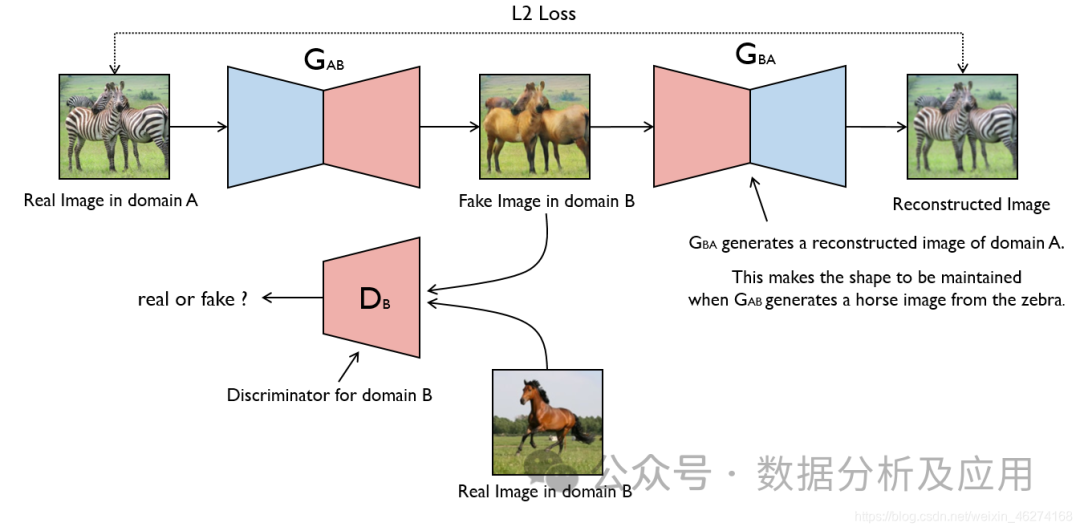
GAN的训练过程是一个优化问题。在每个训练步骤中,首先使用当前参数下的生成器生成假数据,然后使用判别器判断这些数据是真实的还是生成的。接着,根据这个判断结果更新判别器的参数。同时,为了防止判别器过拟合,还需要对生成器进行训练,使得生成的假数据能够欺骗判别器。这个过程反复进行,直到达到平衡状态。
强大的生成能力:GAN能够学习到数据的内在结构和分布,从而生成非常逼真的假数据。
无需显式监督:GAN的训练过程中不需要显式的标签信息,只需要真实数据即可。
难以调试:GAN的调试比较困难,因为生成器和判别器之间存在复杂的相互作用。
数据增强:GAN可以用于生成类似真实数据的假数据,用于扩充数据集或改进模型的泛化能力。
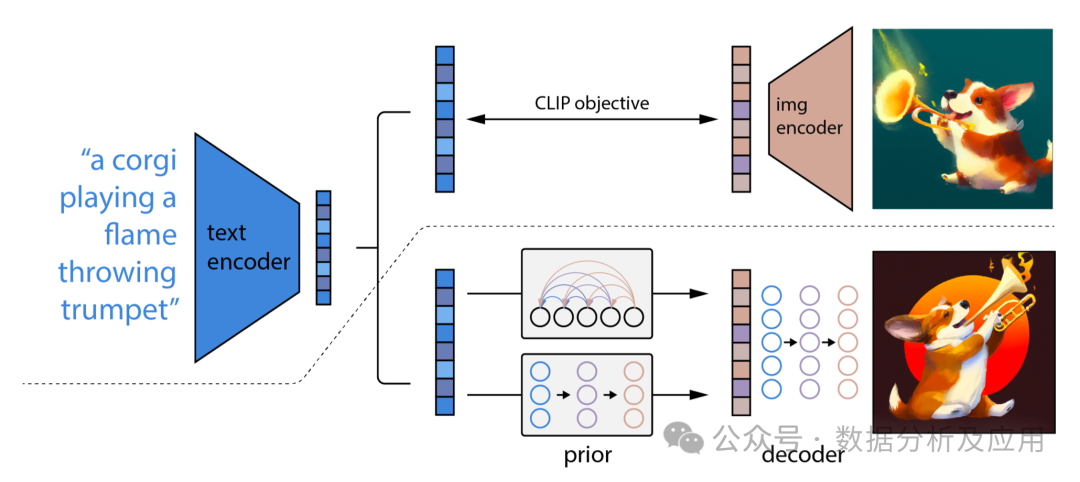
前向扩散:对训练数据集中的每个样本(x_0),按照预定的噪声调度方案,生成对应的噪声序列(x_1, x_2, ..., x_T)。
噪声预测:对于每个时间步(t),训练一个神经网络来预测(x_t)中的噪声。这个神经网络通常是一个条件变分自编码器(Conditional Variational Autoencoder, CVAE),它接收(x_t)和时间步(t)作为输入,并输出预测的噪声。
强大的生成能力:Diffusion模型能够生成高质量、多样化的数据样本。
渐进式生成:模型可以在生成过程中提供中间结果,这有助于理解模型的生成过程。
稳定训练:相较于其他一九游智能体育科技些生成模型(如GANs),Diffusion模型通常更容易训练,并且不太容易出现模式崩溃(mode collapse)问题。
图神经网络(Graph Neural Networks,简称GNN)是一种专门用于处理图结构数据的深度学习模型。在现实世界中,许多复杂系统都可以用图来表示,例如社交网络、分子结构、交通网络等。传统的机器学习模型在处理这些图结构数据时面临诸多挑战,而图神经网络则为这些问题的解决提供了新的思路。
图神经网络的核心思想是通过神经网络对图中的节点进行特征表示学习,同时考虑节点间的关系。具体来说,GNN通过迭代地传递邻居信息来更新节点的表示,使得相同的社区或相近的节点具有相近的表示。在每一层,节点会根据其邻居节点的信息来更新自己的表示,从而捕捉到图中的复杂模式。
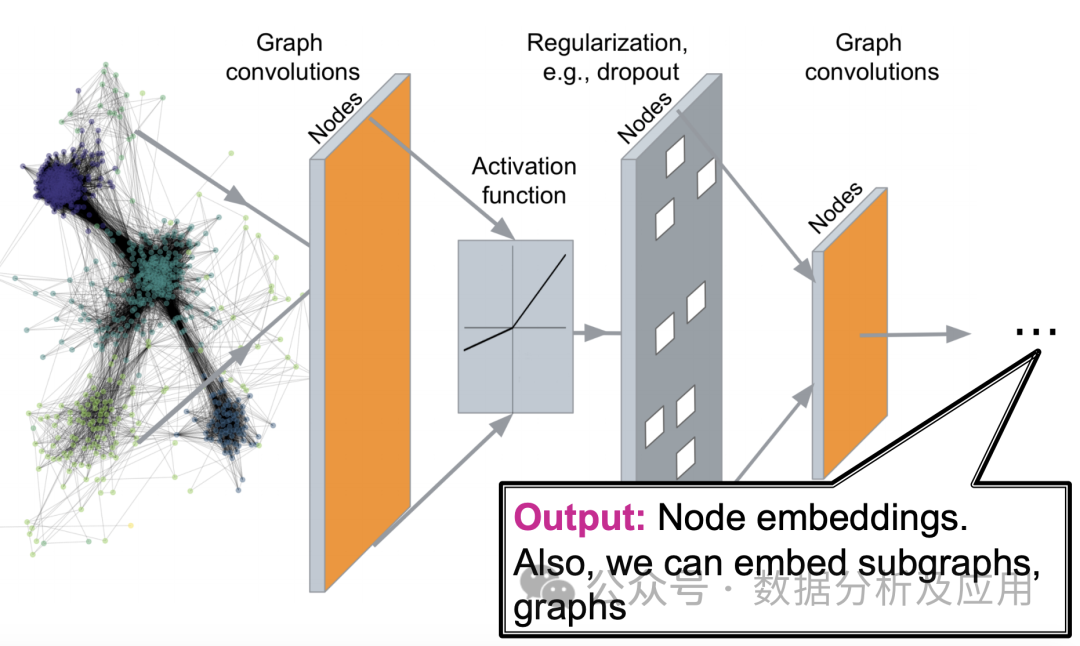
训练图神经网络通常采用基于梯度的优化算法,如随机梯度下降(SGD)。训练过程中,通过反向传播算法计算损失函数的梯度,并更新神经网络的权重。常用的损失函数包括节点分类的交叉熵损失、链接预测的二元交叉熵损失等。
计算复杂度高:随着图中节点和边的增多,图神经网络的计算复杂度也会急剧增加,这可能导致训练时间较长。
参数调整困难:图神经网络的超参数较多,如邻域大小、层数、学习率等,调整这些参数可能需要对任务有深入的理解。
对无向图和有向图的适应性不同:图神经网络最初是为无向图设计的,对于有向图的适应性可能较差。
社交网络分析:在社交网络中,用户之间的关系可以用图来表示。通过图神经网络可以分析用户之间的相似性、社区发现、影响力传播等问题。
分子结构预测:在化学领域,分子的结构可以用图来表示。通过训练图神经网络可以预测分子的性质、化学反应等。
推荐系统:推荐系统可以利用用户的行为数据构建图,然后使用图神经网络来捕捉用户的行为模式,从而进行精准推荐。
在传统的强化学习算法中,智能体使用一个Q表来存储状态-动作值函数的估计。然而,这种方法在处理高维度状态和动作空间时遇到限制。为了解决这个问题,DQN是种深度强化学习算法,引入了深度学习技术来学习状态-动作值函数的逼近,从而能够处理更复杂的问题。
DQN使用一个神经网络(称为深度Q网络)来逼近状态-动作值函数。该神经网络接受当前状态作为输入,并输出每个动作的Q值。在训练过程中,智能体通过不断与环境交互来更新神经网络的权重,以逐渐逼近最优的Q值函数。
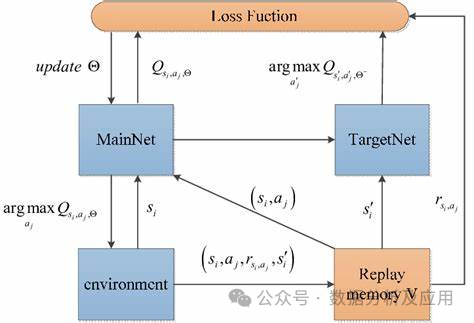
DQN的训练过程包括两个阶段:离线阶段和在线阶段。在离线阶段,智能体从经验回放缓冲区中随机采样一批经验(即状态、动作、奖励和下一个状态),并使用这些经验来更新深度Q网络。在线阶段,智能体使用当前的状态和深度Q网络来选择和执行最佳的行动,并将新的经验存储在经验回放缓冲区中。
不稳定训练:在某些情况下,DQN的训练可能会不稳定,导致学习过程失败或性能下降。
探索策略:DQN需要一个有效的探索策略来探索环境并收集足够的经验。选择合适的探索策略是关键,因为它可以影响学习速度和最终的性能。
对目标网络的需求:为了稳定训练,DQN通常需要使用目标网络来更新Q值函数。这增加了算法的复杂性并需要额外的参数调整。
每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。